Why?
To responsibly test changes before deploying them to production, we need a test environment that behaves, in as many aspects as possible, the same way as our production environment does.
Integration tests should be running in an environment that is as close to production as possible.
We want the ability to reproduce production issues in our test environment for further analysis.
If our test environment only contains engineered test data, we’re going to potentially miss or have trouble reproducing a lot of input data or program state related issues.
Program State Issues
An example of a program state related issue would be having inconsistent data in our database. This would likely lead to undesired application behavior (bugs).
If our test environment only consists of manually engineered database records, it’s possible this bug would be missed in test, making it only detectable in production.
Input Data Issues
An example of an input data issue would be a program that reads CSV files into a database has an issue processing null fields, and some input data contains null fields.
If we only use manually engineered test input data, with no null fields, we will not encounter this issue in test.
Detecting/Reproducing Program State Issues: Mirroring Existing Production State in Test
Copy Down Production Data Stores
In deterministic applications, all program state is driven by input data. That being said, it’s often not possible to replay all input events from all-time or replicate historical one-off manual data migrations performed in production. This is why we should consider copying data stores to replicate application state.
The general idea here is that we want to copy down, from production to test, the data stores our application will interact with (dynamo tables, MySQL databases, etc).
Preferably, you’d do a one-time migration from your production data store to your test data store, and then as an ongoing synchronization method, copy all future state changing events from production to test (as we will talk about in the next section).


If it is not possible to duplicate all input data that changes state into your test environment (from production), the only feasible solution may be to set up timed jobs that copy data from production to test on a periodic basis. There are many tools that support running jobs on a timer, including Jenkins and Rundeck.

Remember, our goal here is to create a test environment that replicates our production environment as closely as possible.
Stateless Applications
If your application is stateless (does not store data), there is no need to implement a data copy down process to mirror existing application state.
Addressing Input Data Related Issues
We want to copy input events from our production environment to our test environment to both detect input data related issues as well as maintain consistency with our production application state (in stateful applications).
Essentially, we need two things:
- A mechanism to copy input data (HTTP requests, events, etc) from production to test. This can be automatic or on-demand with some qualifier.
- Integration tests that incorporate as much real-world data as possible.
Often a combination of existing program state and specific input data are required to reproduce a bug, so it’s important to address both aspects of copying down production data.
Let it Bake
Once developers have a test environment that is comparable to their production environment: the infrastructure is the mirrored, the application state is mirrored, and the data being processed is flowing through both environments, they can let their releases “bake” in test before releasing to production.
Developers can deploy new releases to the test environment, wait a specified period of time, and then compare the output of their test deployment with the output of their production deployment.
A delayed release strategy will lower operational risk by allowing developers to see how their code behaves in a production-like environment before actually deploying to production.
Potential Pitfalls
Data is Confidential
If you are working with confidential data, or other limitations prevent you from copying production data to test as-is, you’ll need to implement a data anonymization process.
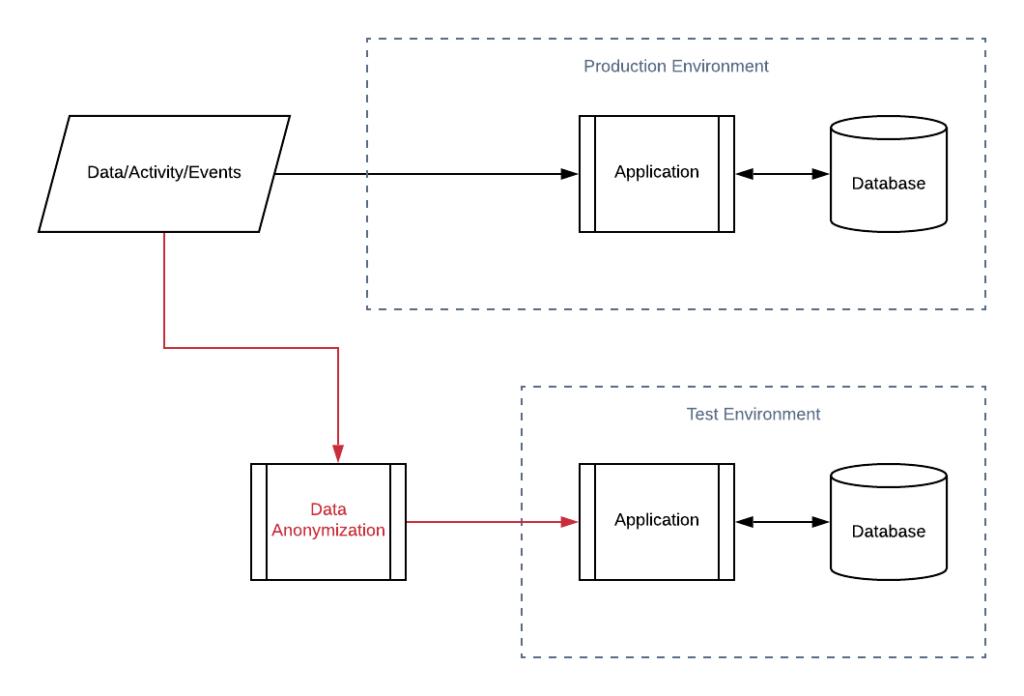
If the fields considered confidential are not processed by the program under test, it may be sufficient to have your copy down process replace those irrelevant values with dummy values without any negative consequence (e.g. if SSN is irrelevant for our app, we can just zero-fill the field when copying down to test).
However, if the fields considered confidential are processed by the program under test, we will need to do consistent replacement.
Consistent Replacement
If you have a field that is considered sensitive and cannot be copied to the test environment, but, the field is used by the application, we must do a consistent replacement when anonymizing the data. Consistent replacement is where we replace sensitive fields with a consistent dummy value, using a persisted mapping, during our anonymization process.

Take, for example, an application that reads in banking records, and indexes transactions in a database by the customer’s last name. If the last name field is considered confidential information, we cannot just randomly replace the field when anonymizing, we must replace the field with a consistent replacement value every time.
If, the customers’ last name was Johnson, and we replace it with Phillips, we must store that mapping (Johnson->Phillips) to ensure every future instance of Johnson is replaced with Phillips when anonymizing future data.
The replacement mappings should be treated as sensitive production data.
Whatever data store is used to store the mappings used for consistent replacement should be very high throughput to avoid bottle-necking the system. I’d consider Redis or AWS DynamoDB for this.
Don’t forget: Your consistent replacement method should also be used when doing the initial data migration.
Example Scopes of Consistent Replacement
- Per input file
- Daily (clear real->dummy cache daily)
- Permanent
Not Feasible Due to Cost or Performance
Here are some things to consider if you are running into performance barriers:
- Limit consistent replacement scope (don’t store replacement mappings permanently if you only need them daily)
- Multi-tenant systems: Only process a subset of tenants
- For stateless applications: Only copy down a subset of production data