
AI prices are going up because frontier AI is still a scarce compute business. They should come down because inference is becoming commodity software.
Both things can be true at the same time.
Why prices are rising
- Capex has to be recovered. The big cloud companies are spending hundreds of billions on AI data centers, GPUs, networking, power, and memory. One current estimate puts 2026 hyperscaler capex around $725 billion, up 77% from 2025. That spend gets pushed into API prices, subscription limits, and enterprise contracts.
- Agents use far more tokens than chat. A single chat answer is cheap. An agent debugging code for an hour can burn millions of tokens across tool calls, retries, file reads, and long context. The old $20/month pricing model was built for chat, not semi-autonomous work.
- The best models still have pricing power. If only a few labs can sell the top reasoning and coding models, they do not need to price them like storage or bandwidth yet.

Why this flips within a year or two
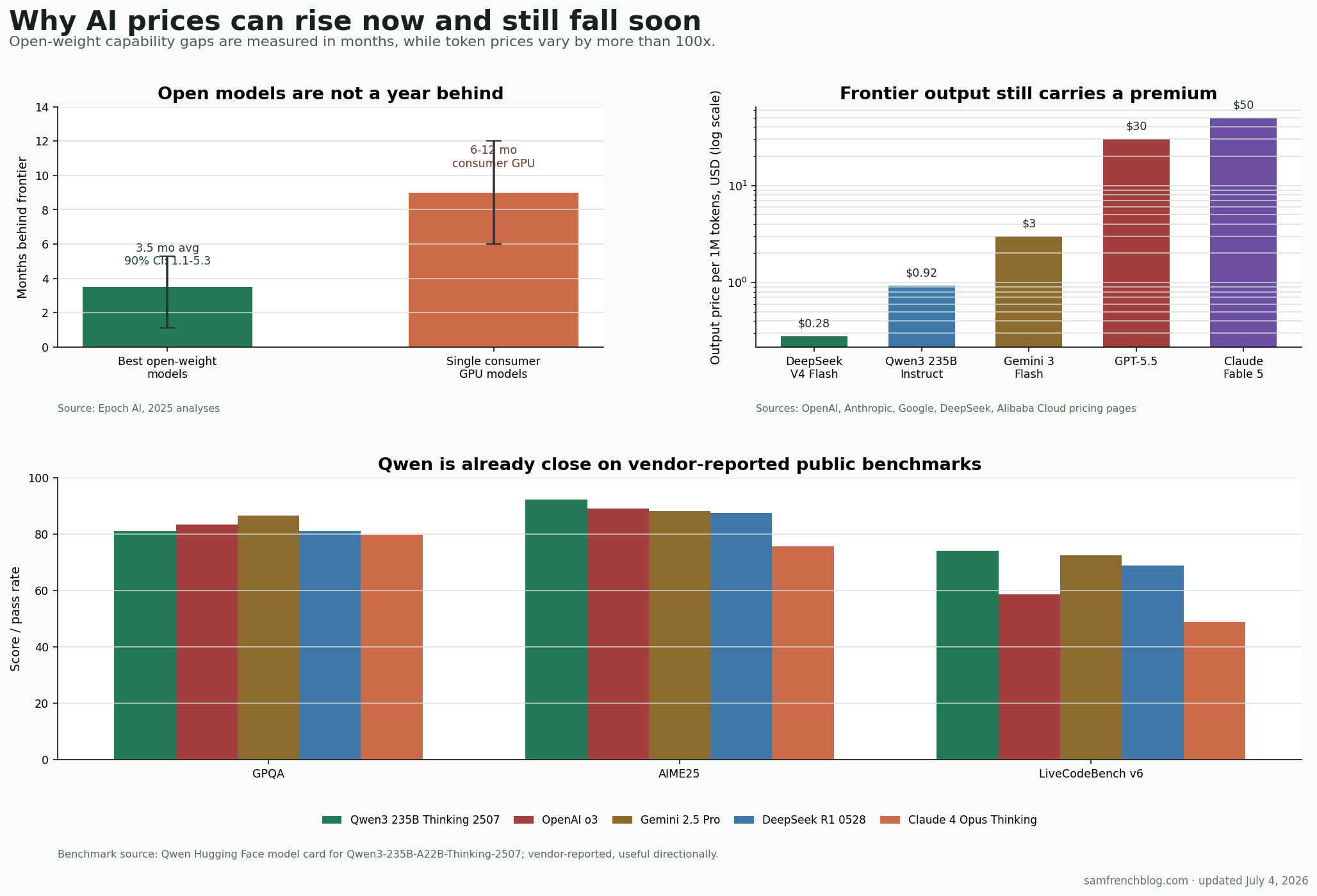
The open-source lag is smaller than I expected. I thought it was roughly six months. Epoch estimates the average open-weight gap at 3.5 months, with a 90% confidence interval of 1.1 to 5.3 months. The six-to-twelve-month number is real, but it applies to models that fit on a single consumer GPU, according to Epoch’s consumer-GPU analysis.
- MoE changes the cost curve. Qwen3-235B-A22B has 235B total parameters but only 22B active per token. That is the point of mixture-of-experts: keep big-model capability without paying full dense-model inference cost on every token.
- Qwen is no longer toy-model territory. On Qwen’s own published table, Qwen3-235B-A22B-Thinking-2507 scores 81.1 on GPQA, 92.3 on AIME25, and 74.1 on LiveCodeBench v6. That puts it near or ahead of named frontier models on those public benchmarks. Treat vendor benchmarks carefully, but the direction is clear.
- Open prices undercut frontier prices hard. Alibaba lists qwen3-235b-a22b-instruct-2507 at $0.92 per million output tokens. DeepSeek V4 Flash is $0.28. GPT-5.5 standard output is $30. Claude Fable 5 output is $50. That spread is too wide to survive commoditization.
- On-device inference takes the boring work off the meter. Summaries, extraction, autocomplete, rewriting, routing, and simple classification do not need the best model. As NPUs and local GPUs get better, more of that work moves to devices you already bought.
What I do about it
- I keep using AI. The price increase does not change the direction of the technology. It changes how carefully I route work.
- I avoid vendor lock-in. Prompts, evals, tools, and data should move between OpenAI, Claude, Gemini, Qwen, DeepSeek, local models, and whatever ships next. The model is a replaceable part.
- I do not sign long contracts at 2026 prices. The current prices reflect scarcity. The next phase is routing, hosting competition, MoE efficiency, and on-device inference.
Sources: Epoch open-weight gap, Epoch consumer-GPU gap, Qwen3 model card, Alibaba Cloud pricing, DeepSeek pricing, OpenAI pricing, Anthropic pricing, Google Gemini pricing.